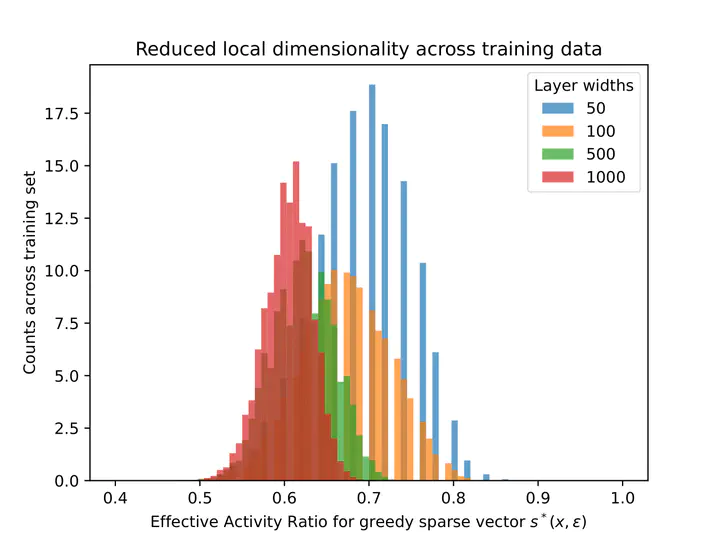
 Effective Activity Ratios
Effective Activity RatiosAbstract
Deep artificial neural networks achieve surprising generalization abilities that remain poorly understood. In this paper, we present a new approach to analyzing generalization for deep feed-forward ReLU networks that takes advantage of the degree of sparsity that is achieved in the hidden layer activations. By developing a framework that accounts for this reduced effective model size for each input sample, we are able to show fundamental trade-offs between sparsity and generalization. Importantly, our results make no strong assumptions about the degree of sparsity achieved by the model, and it improves over recent norm-based approaches. We illustrate our results numerically, demonstrating non-vacuous bounds when coupled with data-dependent priors even in over-parametrized settings.